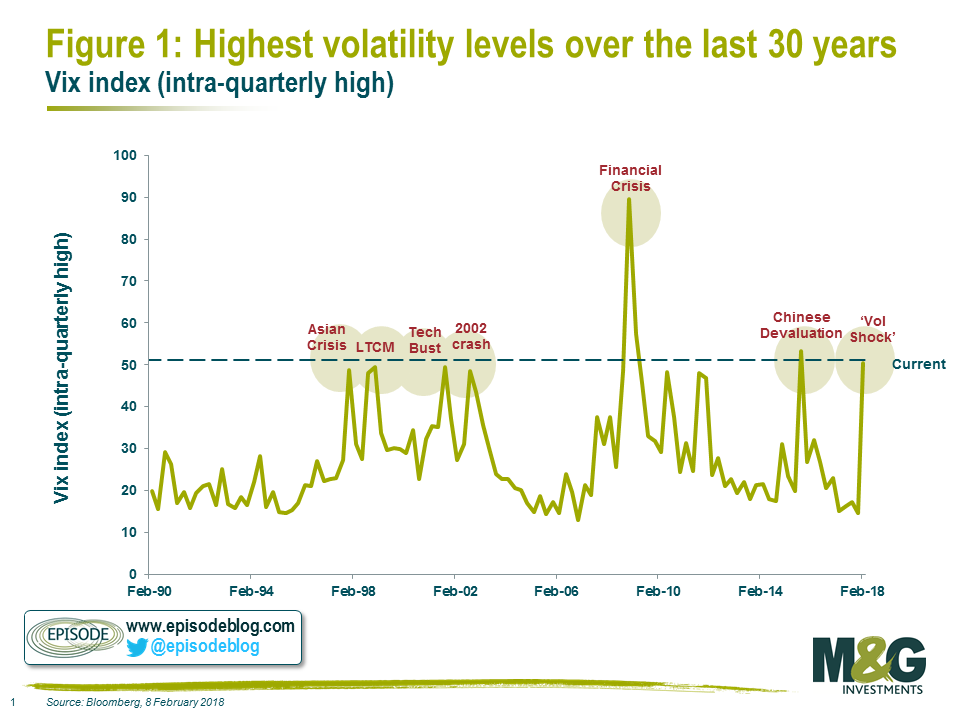
 Source: Episode Interesting look showing how various shocks impacted volatility trading over the past 27 or so years....
Source: Episode Interesting look showing how various shocks impacted volatility trading over the past 27 or so years....
Read More
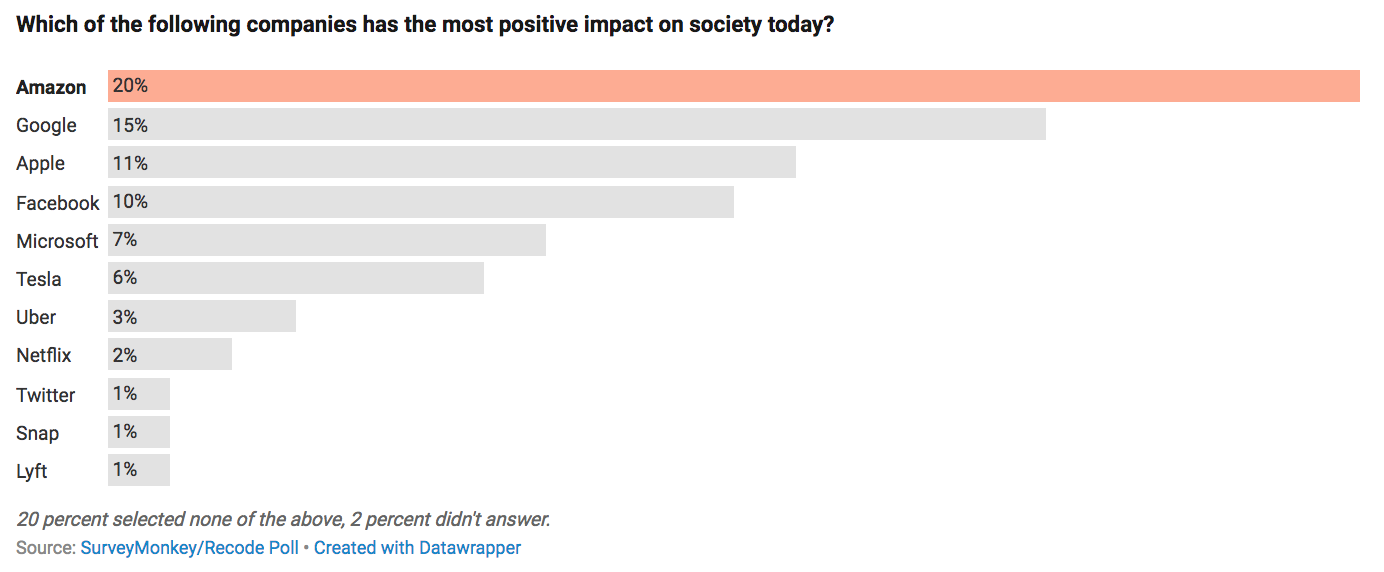 Which of the following companies has the most positive impact on society today? click for ginormous graphic Source: Recode This is...
Which of the following companies has the most positive impact on society today? click for ginormous graphic Source: Recode This is...
Read More
A Millionaire Mindset Never Made Anyone Rich The notion that just thinking something can make it happen is a joke. Too bad some people...
Read More
Investing While Distracted in the Trump Era There’s a lot of sturm und drang out there. The trick is putting it in perspective....
Read More
Small-Business Sentiment Is No Help to Investors Surveys of how entrepreneurs are feeling have proven to be of little value. Bloomberg,...
Read More
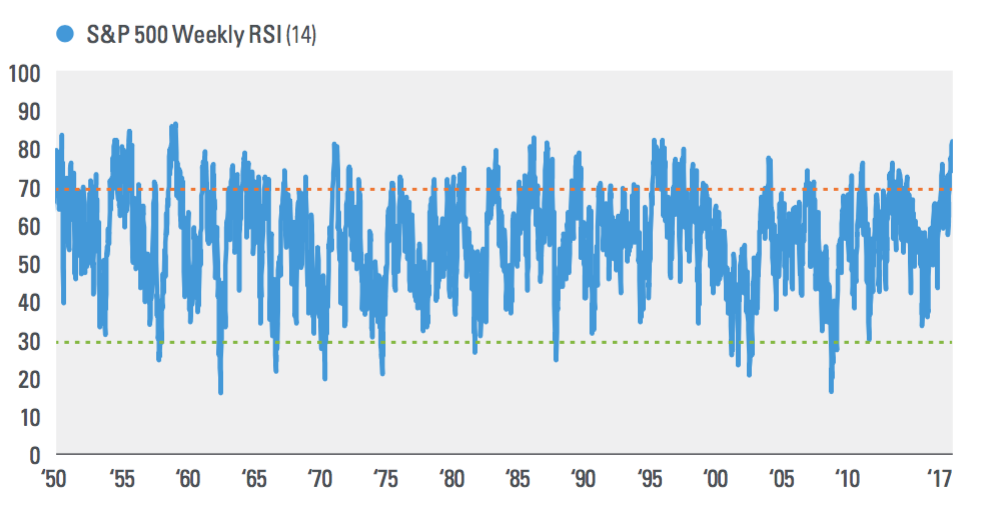 Interesting chart from John Lynch Chief Investment Strategist and Ryan Detrick, CMT Senior Market Strategist, LPL Financial discussing...
Interesting chart from John Lynch Chief Investment Strategist and Ryan Detrick, CMT Senior Market Strategist, LPL Financial discussing...
Read More
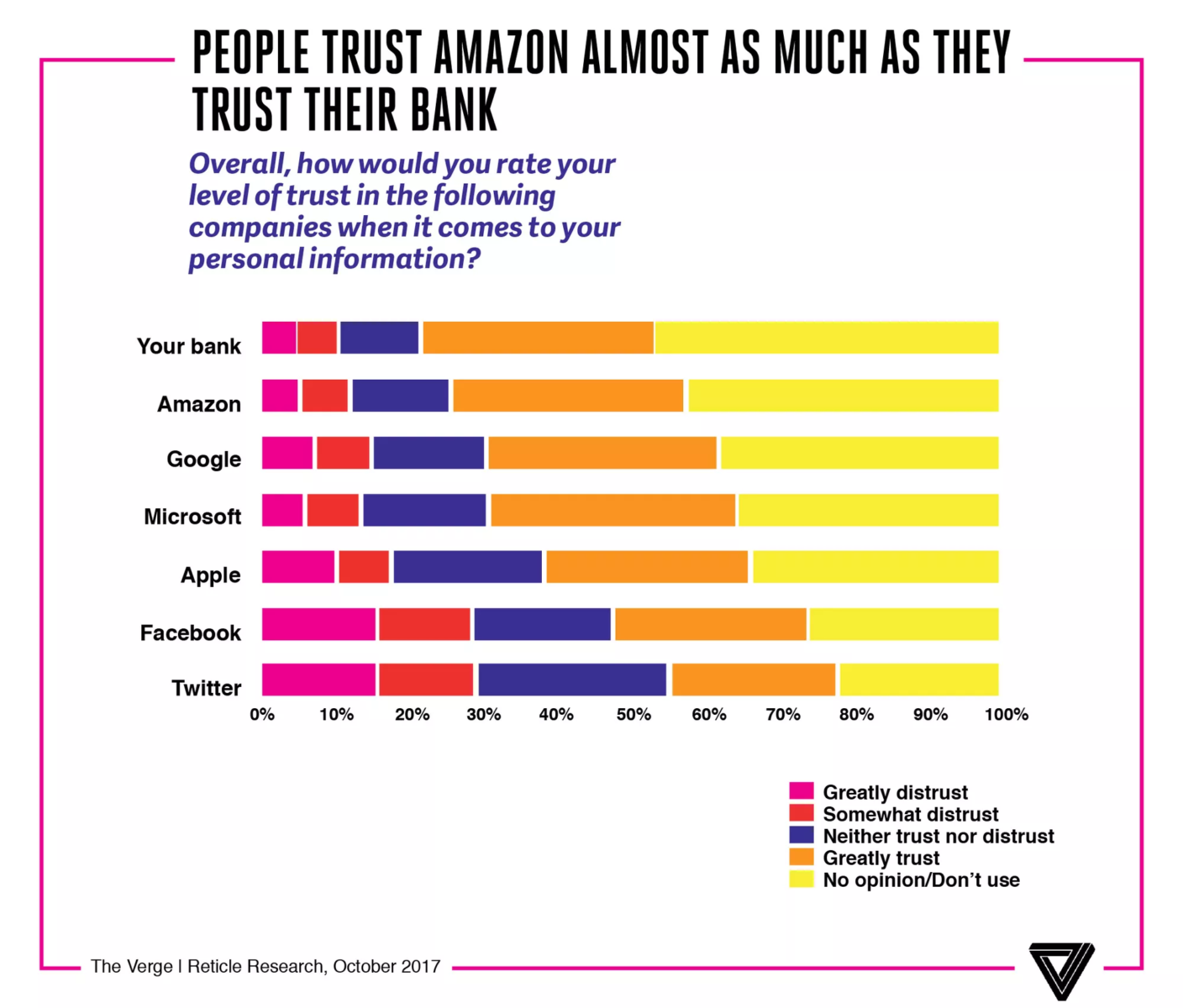 These surveys, via The Verge, are fascinating: “Respondents trusted Facebook less than Google, and “trust” was a primary...
These surveys, via The Verge, are fascinating: “Respondents trusted Facebook less than Google, and “trust” was a primary...
Read More
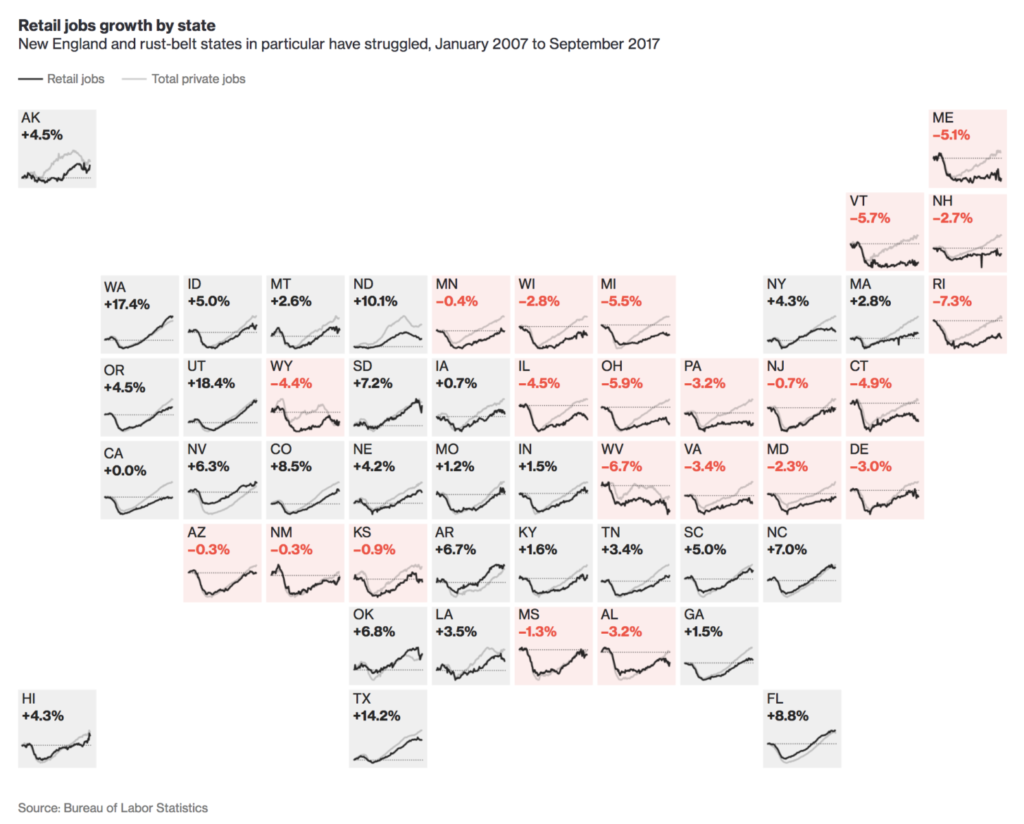 Fascinating discussion at Bloomberg on the pending Retail Apocalypse: “In the U.S., retailers announced more than 3,000 store...
Fascinating discussion at Bloomberg on the pending Retail Apocalypse: “In the U.S., retailers announced more than 3,000 store...
Read More
How to Tell the Bulls From the Bears The same set of facts and events can be seen in very different ways. Bloomberg, October 27, 2017...
Read More
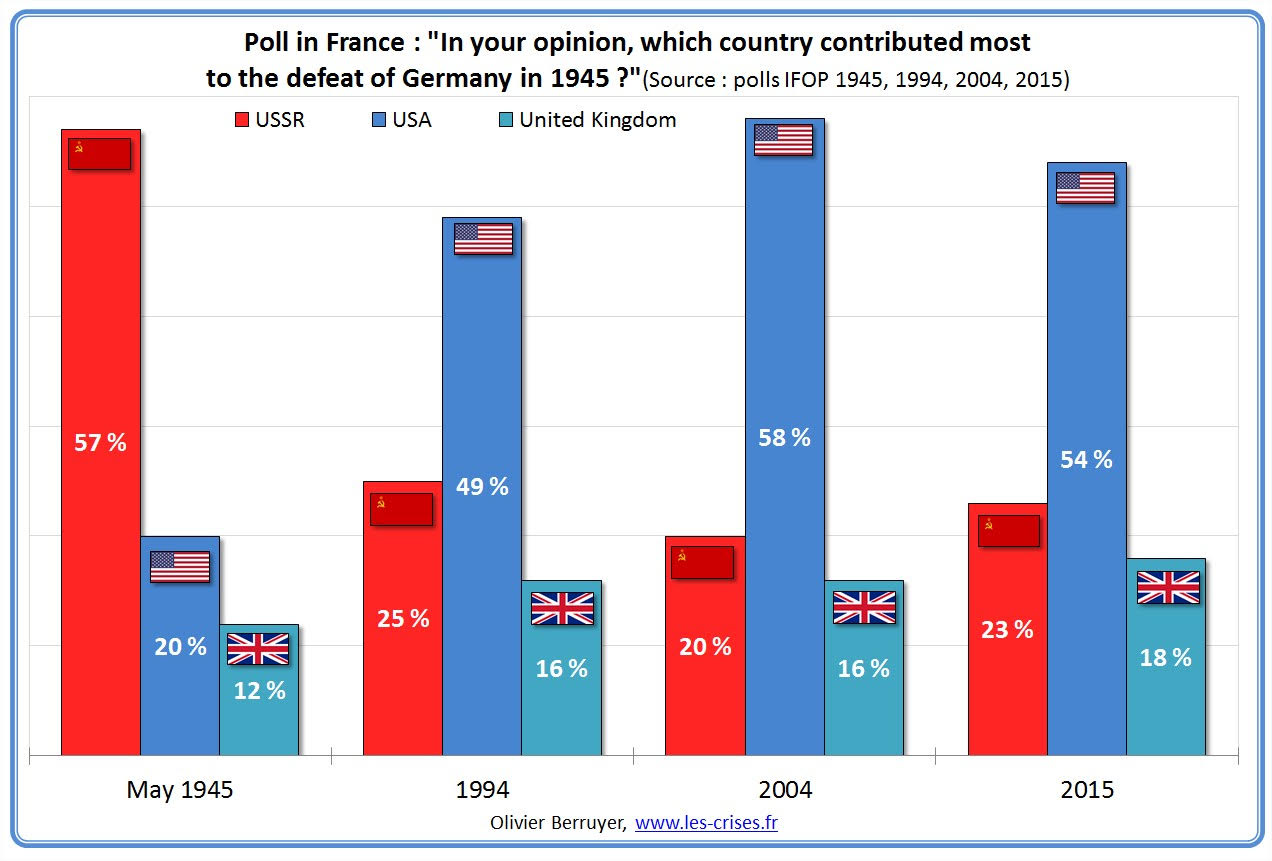 This is a fascinating chart — it shows how beliefs morph – or can be shifted — over time. History, George Orwell...
This is a fascinating chart — it shows how beliefs morph – or can be shifted — over time. History, George Orwell...
Read More
