MIB: Rex Sorgatz and the Encyclopedia of Misinformation
This week on our Masters in Business radio podcast, I speak with Rex Sorgatz, who writes about the intersection of technology and...

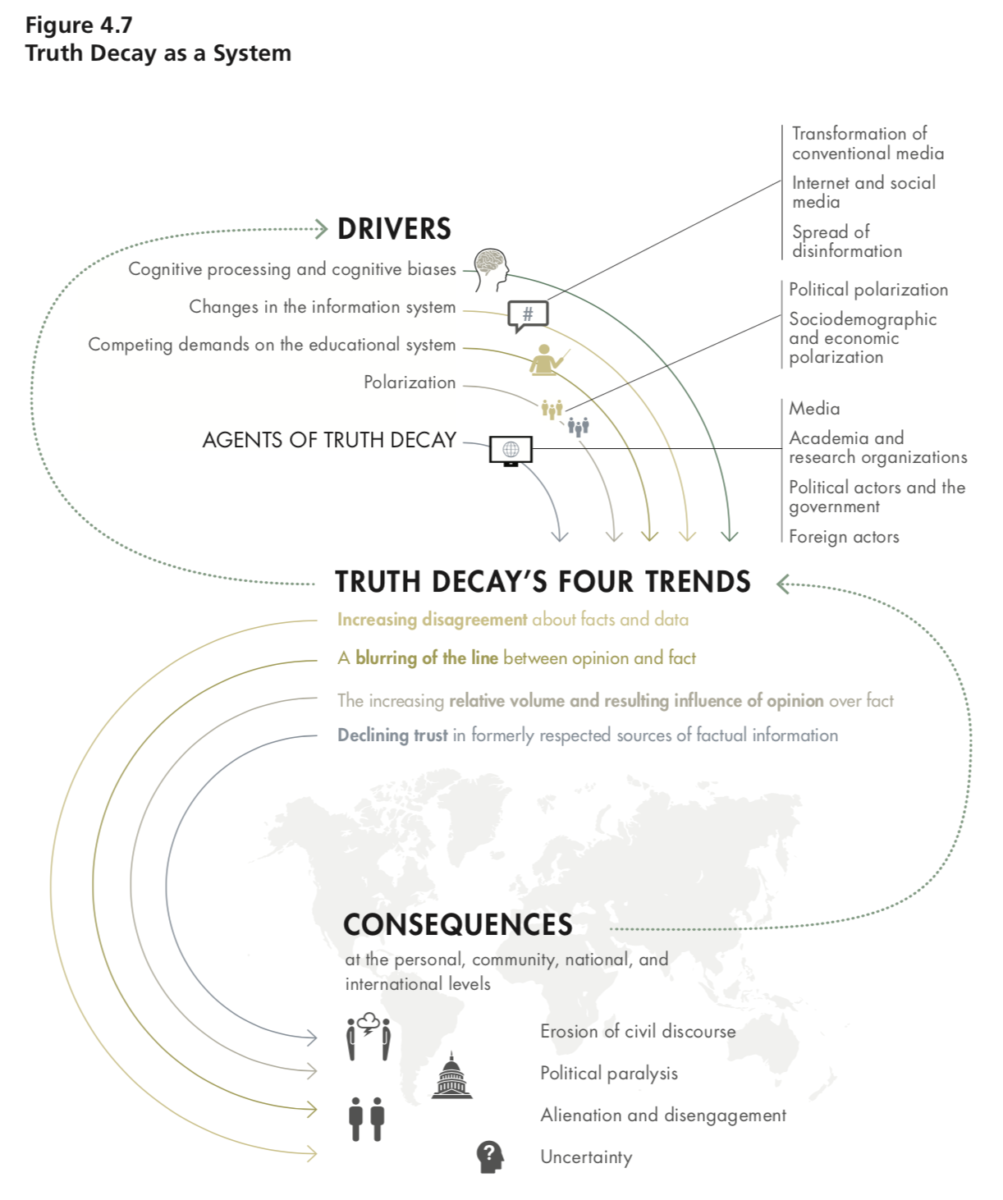 An Initial Exploration of the Diminishing Role of Facts and Analysis in American Public Life Source: RAND Corporation Why is...
An Initial Exploration of the Diminishing Role of Facts and Analysis in American Public Life Source: RAND Corporation Why is...
 Source: RIA Last week, turned 5 years old. We got a very lovely anniversary gift from CityWire RIA magazine, whom we had...
Source: RIA Last week, turned 5 years old. We got a very lovely anniversary gift from CityWire RIA magazine, whom we had...
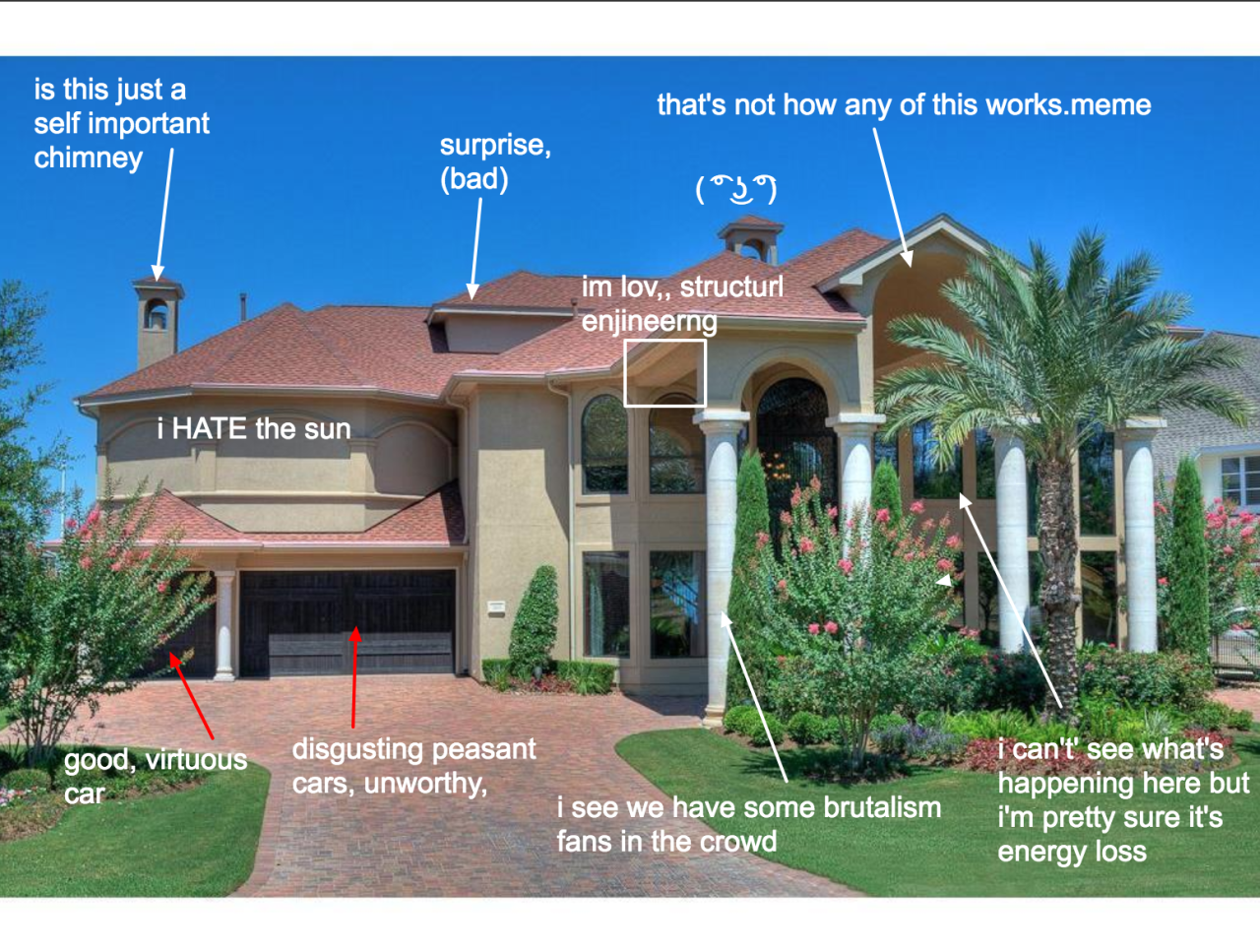 My new favorite real estate blog: McMansion Hell — some of these are genius. Go bookmark the site.
My new favorite real estate blog: McMansion Hell — some of these are genius. Go bookmark the site.
 Facebook Inc. has a fake news problem. Its founder and Chief Executive Officer Mark Zuckerberg doesn’t seem to understand...
Facebook Inc. has a fake news problem. Its founder and Chief Executive Officer Mark Zuckerberg doesn’t seem to understand...
 Nice showing from our team in Become a Better Investors review of best investment blogs with Josh, Mike and Ben all landing...
Nice showing from our team in Become a Better Investors review of best investment blogs with Josh, Mike and Ben all landing...
Get subscriber-only insights and news delivered by Barry every two weeks.
